Distributed Systems
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable. Leslie Lamport As computers have increased in number, they have also spread. Whereas businesses would previously purchase larger and larger mainframes, it is now typical for even very small applications to run across multiple machines. Distributed systems is the study of how to reason about the trade-offs involved in doing so.
I wish I could tell you that this course will empower you to build whatever system you conceive of, but you will soon find out that distributed systems doesn’t work that way! More realistically, I hope to give you the serenity to accept the distributed systems constraints you cannot change, the courage to change the ones you can, and the wisdom to know the difference.
 A note about assumed knowledge: distributed systems tends to combine concepts from operating systems, computer networking and databases in particular. For most people, it would make sense to leave the study of distributed systems for last, so I will take as assumed knowledge some of the core concepts of those other topics. That being said, if you are excited to dig in to distributed systems now, don't get yourself stuck working on earlier courses! You're of course welcome to dive in here, then dip in and out of other courses as you identify any gaps in your understanding.
A note about assumed knowledge: distributed systems tends to combine concepts from operating systems, computer networking and databases in particular. For most people, it would make sense to leave the study of distributed systems for last, so I will take as assumed knowledge some of the core concepts of those other topics. That being said, if you are excited to dig in to distributed systems now, don't get yourself stuck working on earlier courses! You're of course welcome to dive in here, then dip in and out of other courses as you identify any gaps in your understanding.
This course follows the sequencing of the excellent textbook Designing Data-Intensive Applications (“DDIA” below). While not a traditional academic text, it does a surprisingly good job of combining the principles and practice of distributed systems in what is a rapidly developing field. Kleppmann brings much needed pragmatism to the topic, without compromising the generality or strengths of the underlying theory, making this my favorite overall distributed systems book.
Note from Oz: distributed systems is more concept-heavy, so we'll lean more on seminars compared to other CS Primer courses. We will also use "vicarious learning" style system design modules, as well as a project sequence of a simple distributed key-value store (expected release January 2026).
Introduction
Our first module will cover the important terms and themes we’ll be encountering throughout the course. We will also discuss a few system failure post mortems to motivate the remainder of the course. In preparation, please read chapter 1 of DDIA.
Problems
| KV store: introduction | start building out your distributed key/value store, first as a single node (1:03:13) |
Seminars

Explainers
Communication and encoding
When one node in a distributed system needs information from—or work done by—another node, it must express this desire in the form of a message, and transmit it over a shared communications channel.
For information to be effectively communicated, nodes must share an understanding of how it’s encoded. In this module we’ll examine the encoding and decoding strategies used by a number of popular transmission formats, and discuss some general principles of protocol design. We will then apply these principles and draw inspiration from the transmission formats we’ve seen to design our distributed key value storage protocol.
In preparation, please read chapter 4 of DDIA, with a particular focus on the introduction and “Formats for Encoding Data” sections.
Seminars


Replication
Redundancy is central to any reliable distributed system. A component that may fail in a system requires at least one alternative, which the system must know when to utilize.
To provide such alternatives in a system used for retrieving data, we must replicate the data. We will explore replication as the primary source of fault tolerance, discuss how we might increase the fault tolerance of our distributed key value store, and examine techniques used by more sophisticated systems in practice.
In preparation, please read through DDIA chapter 5 (Replication) up to but not including “Leaderless Replication”, which will be covered later
Seminars

Partitioning
Partitioning is unavoidable in some systems: we may simply have too much data to fit on the hardware available to a single node.
But storage capacity is not the only challenge for which partitioning can be a solution. Any hardware bottlenecks—like throughput of storage, communication or compute—can motivate us to partition data across multiple nodes, thereby increasing overall throughput.
In this module, we’ll explore the overall role of partitioning in increasing scalability, and apply our understanding to our key value store project.
The relevant chapter of DDIA is chapter 6, and I would encourage you in particular to focus on “Partitioning of Key-Value Data”.
Seminars
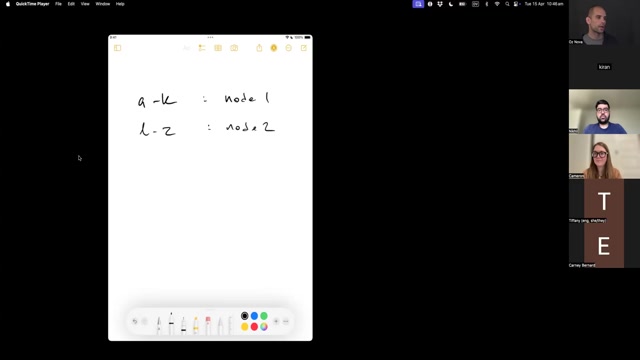

Consistency and consensus
In this module, we’ll examine some ways that seemingly consistent designs can still produce subtle and not-so-subtle inconsistencies. Even though all distributed systems are inconsistent by default, it is possible—with great effort—to build distributed systems that are consistent to the degree that components agree on important data values.
We will discuss the trade-offs required to achieve this “consensus”, broadly how it may be implemented, and how it is used by distributed systems in practice.Chapter 9 of DDIA is a challenging but worthwhile supplement
Seminars
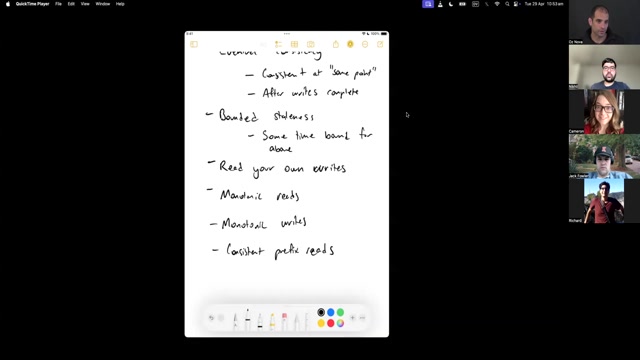

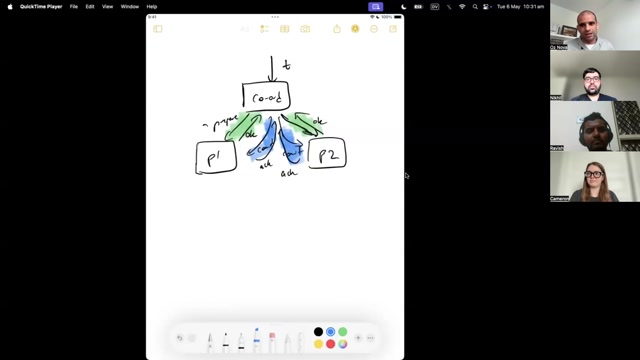

Patterns of distributed data access
In this module, we will cover some of the common distributed systems patterns, and how they each apply the core principles with their own considerations and tradeoffs. DDIA pays particular attention to leaderless key-value stores, batch processing and stream processing. I would encourage you to focus on whichever areas you find most relevant, and return to any others when the need arises.
Seminars




System design
Now that we have all of the conceptual pieces of distributed systems, we'll put it all to practice in the form of system design problems. These are presented in a "vicarious learning" structure where a problem is posed to another student, who works through it and is given feedback. The video will pause for you to work through parts of the problem too.
Problems
| Dictionary search | design the search functionality for an English language dictionary website (52:50) |
| Thesaurus scraper | design a system to build a thesaurus from scraped web data (1:19:39) |
| Log aggregator | design a small system to aggregrate logs from a handful of others (1:22:29) |
| Image rescaler | design a system to generate image thumbnails from uploads (1:03:44) |