Algorithms and Data Structures
It is foolish to answer a question that you do not understand. It is sad to work for an end that you do not desire. George Polya Algorithms and Data Structures can be a particularly rewarding area of study, because it drives at the core of computer programming: solving difficult problems.
In the course below, you’ll learn a number of important data structures and algorithms, which we’re sure will prove useful throughout your career. Just as importantly, you’ll develop a stronger ability to understand, break down and solve novel problems, whether inventing your own techniques or repurposing those which you learn here.
At the core of this course are the sequences of problems for each topic. You should aim to solve each problem, using the worked solutions and supplementary explainers as needed. For more suggestions on how to approach CS Primer, see the how-to guide.
Also included are seminars recorded with CS Primer students, which you may like to work through as well, by stopping and asking yourself each of the questions we cover together. These were typically recorded after the students completed 1-2 problems in that module, so are designed to reinforce the fundamental concepts and prepare for harder problems.
 As a supplementary resource, I recommend Steven Skiena’s video lectures and book: The Algorithm Design Manual. This tends to be a little less heavy in theory, and has a more "problem solving" orientation than the typically recommended textbooks. There are plenty of other good resources available online, such as those from Tim Roughgarden. Generally I suggest just attempting the problems below, and reaching for the textbook if you feel conceptually stuck or would like further practice problems.
As a supplementary resource, I recommend Steven Skiena’s video lectures and book: The Algorithm Design Manual. This tends to be a little less heavy in theory, and has a more "problem solving" orientation than the typically recommended textbooks. There are plenty of other good resources available online, such as those from Tim Roughgarden. Generally I suggest just attempting the problems below, and reaching for the textbook if you feel conceptually stuck or would like further practice problems.
Problem solving
In the words of Richard Hamming: "I have faith in only one [methodology] which is almost never mentioned—think before you write the program".From The Art of Doing Science and Engineering, best known for its inspiring chapter and corresponding lecture You and Your Research In this short warmup sequence, we practice actually thinking about technical problems, using a method modeled off George Pólya's How to Solve It.
Problems
| Staircase ascent FREE | crack a challenging programming problem using some techniques from Polya (31:06) |
| Convert to Roman | convert an integer to Roman numerals without a bunch of "if" statements (18:19) |
| Correct binary search | implement binary search without any edge case bugs using invariants (18:41) |
Seminars

Explainers
Asymptotic analysis
The analysis of algorithms is a huge field—to which some computer scientists dedicate their entire livesOne such devotee is Donald Knuth, who started writing The Art of Computer Programming in 1962 and has published approximately half of his planned volumes. but by the end of this module you should be able to assess the time and space cost, in Big O terms, of most of the programs you’ll encounter in the wild.
Problems
| Finding duplicates | assess three different approaches to the same simple problem (34:23) |
| Fizzbuzz sum | given an obvious linear time solution, look for a logarithmic or constant time one! (23:44) |
| Just iterate | measure to find out when simple iteration beats binary search (22:53) |
Seminars

Explainers
Linear structures
This module covers stacks and queues: how they are useful, but also how they can be implemented using dynamic arrays and linked lists.
While these are not necessarily the most exotic or exciting data structures, it's very useful to be familiar with them, because:
- Queues appear throughout software systems, as a way to buffer data that preserves order
- Stacks appear throughout software systems, as a way to easily access the data that was most recently handled
- Linked lists are actually not terribly useful in their own right—at least compared to using dynamic arrays in their place—but working with them gives us good practice for trees and graphs, which are effectively linked lists with branchesConsider that a tree is a special kind of graph where no node has more than one parent. A linked list is a special kind of tree where no node has more than one child.
- Being able to remodel a recursive function as one with an explicit stack can give us significant constant factor improvements, and in some contexts avoid overflowing stack memory. This can be particularly useful for depth first searches.
- Overall familiarity with stacks and queues will help tremendously with depth first and breadth first search respectively: these algorithms are intimately linked to these data types
Problems
| Parenthesis match | practice using a stack, by checking code for matching parentheses (39:50) |
| Doubly linked list | implement a deque data structure as a doubly linked list (49:34) |
| Basic calculator | see how stacks help us work "inside out" by implementing a basic calculator (40:46) |
Seminars

Explainers
Divide and conquer, and sorting
Divide and conquer is a broadly applicable problem solving strategy, renowned for producing astonishing results.One astonishing result is the Karatsuba algorithm for fast multiplication of two n-digit numbers. The renowned complexity theorist Kolmogorov had conjectured that the fastest possible multiplication algorithm was O(n2), and presented this conjecture at a seminar in 1960 attended by the then 23-year-old Karatsuba. Within a week, Karatsuba had disproved the conjecture, finding an O(nlog23) algorithm using an approach which would later come to be named divide and conquer.
This caused Kolmogorov to become wildly excited, terminating the seminar series and publishing and article on the result in Karatsuba’s name, kick starting a period of intense interest in the area.
The history of the result is detailed in Karatsuba’s later paper The Complexity of Computations. Pictured below is Karatsuba as a high school graduate, a few years before his remarkable discovery.

We’ll explore the idea generally, as well as in the context of sorting. Here we’ll explore the problem until we’re convinced that it can be done at no better than O(n2), and be duly impressed by two divide and conquer based algorithms that manage to run at the much better O(n log n)! It’s uncommon—though a rare pleasure—to implement your own sorting algorithms from scratch, so instead we’ll focus our discussion on the overall strategy, as it can be applied in many domains outside of searching and sorting.
Problems
| Merge sort | implement the truly mind blowing faster than O(n^2) merge sort algorithm (1:15:55) |
| Fast exponentiation | find a shortcut for raising an integer to a power (23:03) |
| Quicksort | implement the iconic quicksort algorithm (39:15) |
Seminars

Tree traversal and graph traversal
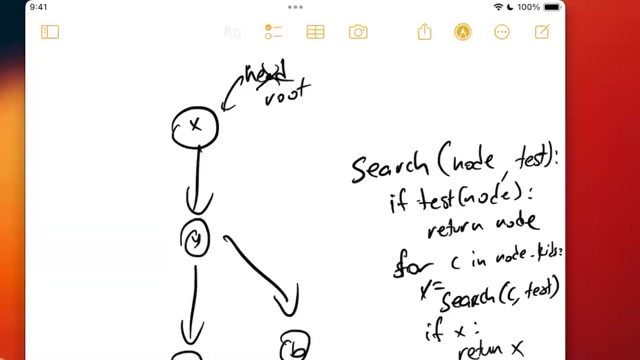
If we had to choose a single Greatest Hit of algorithms, it would be graph search. It’s tempting to give examples where graph search shines,The stereotypical examples are social networks, the web and the internet. But if we were to emphasize these examples, you’re likely to come away with a narrow view of what is in fact a very broadly applicable tool. but by the end of this module you’ll actually appreciate that almost anything can be modeled as a graph and almost any problem can be solved with graph search.
In this module we’ll start with simple breadth first and depth first traversal over trees, then first extend our use of these algorithms to graphs. While already very powerful, we can further extend these techniques to searching over weighted graphsA weighted graph is one where the strength of the relationship between two entities matters, which we model by assigning a “weight” value to edges. which turns out to be a common problem.
To search over weighted graphs, we introduce two important algorithms: Dijkstra’s algorithmWhile we stick with the convention of calling this algorithm Dijkstra’s, the better name—used more in the AI community—is “uniform cost search”. Dijkstra was the first to develop many algorithms, but this one was well known to others before Dijkstra re-discovered it. Furthermore, “uniform cost search” begins to describe its approach: the frontier of the search is defined by points of equivalent cost. and A*.Pronounced “A-star”, this algorithm was developed at Stanford Research Institute to help Shakey the Robot navigate obstacles in a room. At the time, Dijkstra’s algorithm was the best path planning option available. A* was seen as a minor enhancement to the algorithm, but the improvement in efficiency was very significant.
Pictured below is Shakey on display at Computer History Museum.

Using A* search in practice is all about finding suitable “heuristic functions”, which are measures of how close we are to our goal. We’ll practice this skill on problems where the choice of heuristic function makes a significant difference.
Problems
| Process tree | reformat the output of ps to show how the processes are related (1:08:53) |
| Word ladder | solve a classic Lewis Carrol word game with graph search (1:27:35) |
| Jug pouring | find graphs in unexpected places (50:22) |
| Knight's tour | solve a classic problem in graph theory, the fun way (53:19) |
| Maze solver | find a good path through a maze, in the style of a game AI (55:55) |
Seminars



Explainers
Dynamic programming
This class ensures that your recursive thinking is not in vain, by introducing dynamic programming: an important technique to avoid unnecessary computation and render certain recursive problems tractable.The name “dynamic programming” could certainly be more descriptive. Richard Bellman claims in his autobiography that he chose these words because it’s impossible to use the adjective “dynamic” in a pejorative sense, and because the practical connotation of the word “programming” would appeal to the research-averse Secretary of Defense of the time (who was indirectly responsible for his funding).
This story may not quite be true; an alternative account suggests that he was trying to “upstage Dantzig’s linear programming by adding dynamic”. For more, see the dynamic programming Wikipedia article. Dynamic programming has proved invaluable in applications varying from database query optimization to sequence alignment in bioinformatics.
Problems
| House robber | find an optimal subset of integers avoiding adjacent pairs (47:18) |
| Perfect squares | what are the fewest square numbers needed to sum to the integer n? (32:42) |
| Minimal grid path | find the minimal path through a grid (54:00) |
| Edit distance | how many changes occurred between two given strings? (54:08) |